After watching a near-by project fail, related to in-memory data grid and complex event processing, I set myself to find a different approach from the major SW vendors, that I could use on one of my projects. That’s when I found Hazelcast (http://hazelcast.com), a an in-memory open source software data grid based on Java.
For a Java programmer it has an easy step-by-step learning curve, from a simple distributed key-value store to an in memory Map-Reduce enabled application. Mainly because HZ builds on top of the existent Java Collection objects, distributing them seamlessly.
So I started with a simple String/JSON key-value store.
For a Java programmer it has an easy step-by-step learning curve, from a simple distributed key-value store to an in memory Map-Reduce enabled application. Mainly because HZ builds on top of the existent Java Collection objects, distributing them seamlessly.
So I started with a simple String/JSON key-value store.

The IMap class above is a special Map implementation that extends it, enabling distribution and redundancy of the content between nodes in a cluster. However it can be treated as a single Map, accessed on each Hazelcast instance (aka node), typically resident on a different machine. That allows adding the in-memory grid by the RAM present on each machine (horizontal scalability).
Inserting data on the key/value store is as easy as any other Map.
Inserting data on the key/value store is as easy as any other Map.

Creating a cluster for sharing the store can be accomplished by multicast group or configuring specific tcp/IP participant members. The great advantage is that each node can use its computation unit independently, and access the same data store.
Hazelcast takes this even further: you can use the nodes not only to store data but to compute whatever you want. And we’re not even talking of MapReduce yet :)
The code bellow illustrates the creation of an executor service that spawns to every node of the cluster, (Calculating sales performance for each Month, for eg.). Each node uses the local machine to handle the computations and can update the shared data store. The problem here is thinking how to effectively handle truly distributed code ;)
Hazelcast takes this even further: you can use the nodes not only to store data but to compute whatever you want. And we’re not even talking of MapReduce yet :)
The code bellow illustrates the creation of an executor service that spawns to every node of the cluster, (Calculating sales performance for each Month, for eg.). Each node uses the local machine to handle the computations and can update the shared data store. The problem here is thinking how to effectively handle truly distributed code ;)

From here to Map Reduce is an ‘easy’ gap.
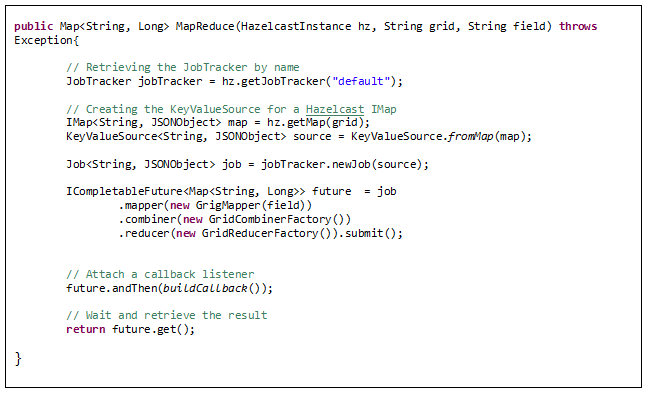
I’m not getting to specific; the purpose of this article is just to show how easy it is to work with HZ and some of its features. If this meets some of your requirements (in-memory computation, distributed workloads or scalable architectures), give it a try and get hooked!
Share your thoughts/experience with Hazelcast.
Share your thoughts/experience with Hazelcast.

 RSS Feed
RSS Feed
